Osiyo. Dohiju? Hey, welcome back.
Tesseract is a great Optical Character Recognition (OCR) program. OCR is, simply, the ability to take an image and find the text included in it and pretty accurately return that as plain text. There are a couple implementations of it out there including an all Javascript version. I’m going to cover some very basics of Tesseract and processing images with one and two languages. I’ll also identify some issues with processing such as if the image has a table or one language processing but there are two languages in the image.
For these purposes, I’ll use command line (CLI) for Mac, Debian, or Windows Subsystem Linux (WSL). These are all very similar to use. If you want to use another approach feel free to read the documentation. To start, go to https://github.com/tesseract-ocr/tesseract/wiki and you can find how to install on your particular computer. For me, I’m going to cover Debian and Debian WSL. If you don’t have Debian for your Windows 10 computer installed go to the Microsoft Store on your computer and search for ‘Debian’ then install and restart. Open Debian WSL and then it’ll ask you for a new user and password, put those in and you’re ready to begin with these tutorials.
Open your Debian CLI or Debian WSL. Type in ‘sudo apt-get install tesseract-ocr’ then hit Enter. Once that’s finished installing you can type ‘sudo apt-get install tesseract-ocr-chr’ where ‘chr’ is whatever language other than English you want to OCR. Once the language is installed we’ll move to the next section.
I’ve got some examples I’m going to show you using Cherokee and English as the two languages from a book by a friend of mine. With Debian WSL you’ll need to find the directory where your images are that you want to use. If they are on your Windows system then you’ll have to cd to /mnt/c/ and then whatever directory they are in. If you don’t know how to use a Debian or Linux system you should read up on that.
I run hundreds of images at a time through processing. I generate a shell script using Groovy then run that shell script. I’ll include some examples, however, if you don’t know how to use Groovy then you’ll have to read up on that as well.
The basic command line structure for Tesseract is “tesseract -l <language> <imageName> <outputTextFile>”. For this we’ll be using the language code ‘chr’ (for Cherokee) and ‘eng’ (for English). Tesseract allows you to use both languages together and it attempts to figure out which one to use. For that the ‘-l’ option is ‘-l chr+eng’. The images below vary in complexity for the purposes of this, very brief, tutorial.
The first image is simple in English and Cherokee. The second example is more complex involving tables, some Cherokee, and diacritical marks. The third example is quite complex with English and Cherokee mixed.
Running ‘tesseract -l chr+eng <imageName> <outputFileName>’ – here are the different results. I’ve made these a screenshot to be able to compare the two.


You can see there are no obvious mistakes right off. Most of the words are correctly identified. It isn’t until you look a little closer that the third line didn’t get correctly picked up. I don’t know if that’s because of the background grain and possibly bleed. Like maybe the pages should be run through OpenCV first. In any case, it does a pretty good job on a simple page like this; only a few mistakes to correct.
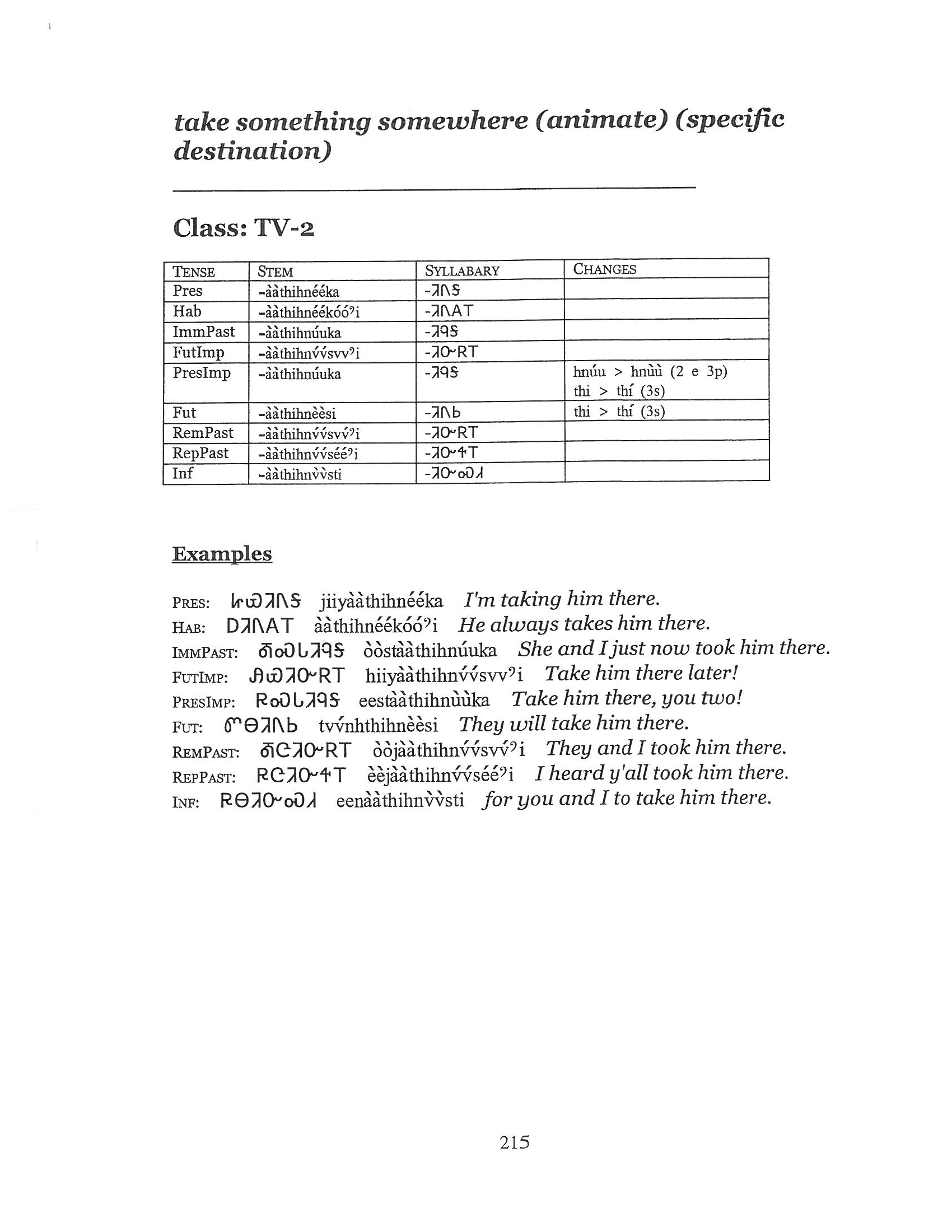

In this set, you can tell that Tesseract didn’t do as well. The tables aren’t replicated – which is ok as this is OCR and not some kind of document re-creation software. There are far more mistakes with this page (not including the table). You can see “IMmPast” instead of all the same “ImmPast” or even “IMMPAST.” You can also see a lot of issues with text in the table and text in the examples getting munged a little. Still – not bad. Not all of the diacritical marks, which is probably ok. I’ll have to look more into why that is and maybe there’s a solution that I don’t know. All-in-all still something to work with. Probably better than hand typing everything, but idk how much time it would take for me to compare and fix compared to retyping and then generating the Cherokee on the fly like I do with the dictionary site.



With this last set the English portion seems to be ok. The Cherokee portions don’t turn out so well. I think this is because of the leading dash (-). Which makes Ꮿ (‘ya’) come out as a ‘W’. This did a lot of work so most of the fixes you can see are related to the syllabary. Still, a lot of work that doesn’t have to be retyped.
This particular book is one of the more complicated works. I’ve used Tesseract many times with digitizing images to an editable text format. This is only meant to be an overview of Tesseract and some items to remember when converting images to text. Tesseract does a good job at what it knows how to do. I don’t know what the time saved retyping pages is in the end. I suppose that speed is determined by how fast someone can type vs comparing an image with text. Especially since this is two languages. For me, as I said above, I would convert the text like has been done then compare each side by side and use the transliteration engine I wrote to facilitate in syllabary in the text. When that’s complete then I’d leave the syllabary in the text since the conversion cycle is now done.
I hope this gives you something to think about. I’ll probably look more into why the diacritical marks aren’t all showing up.
Until next time. Dodadagohvi.
